一、注册百度云账号然后选择百度语音功能
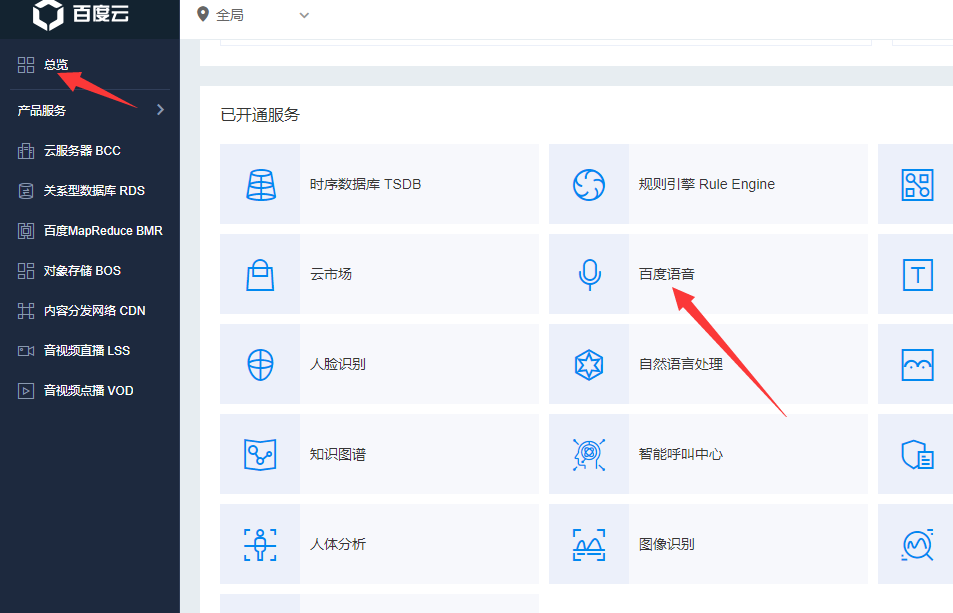
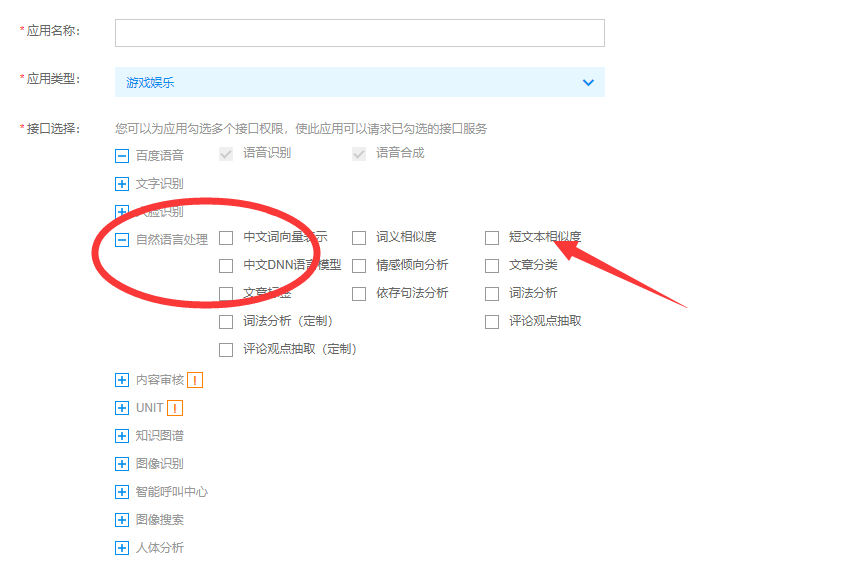
二、创建百度语音的应用:

全部选择默认或者针对选择你所需要的功能就可以了
然后查看你所创建的内容:
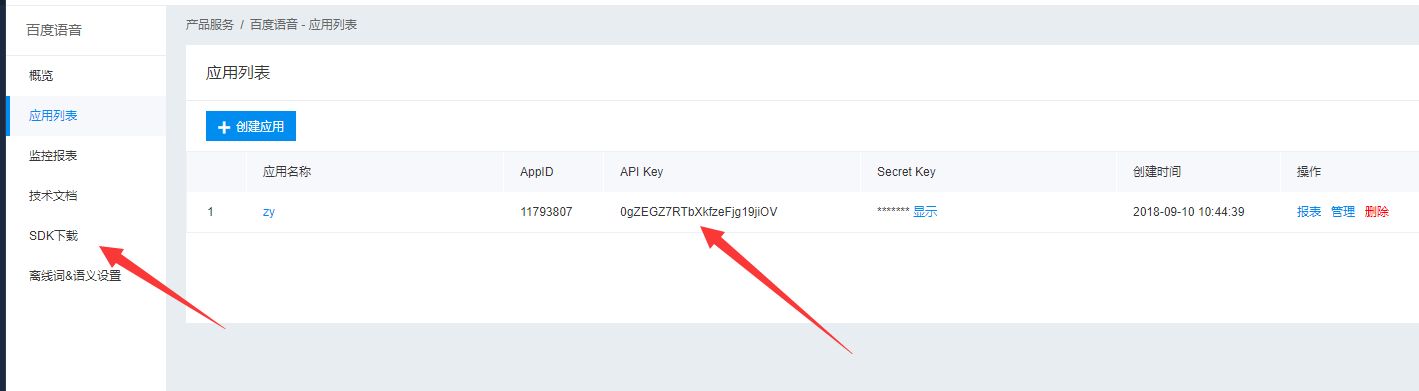
根据左侧的技术文档然后进行查看
选择百度语音中python的语音识别
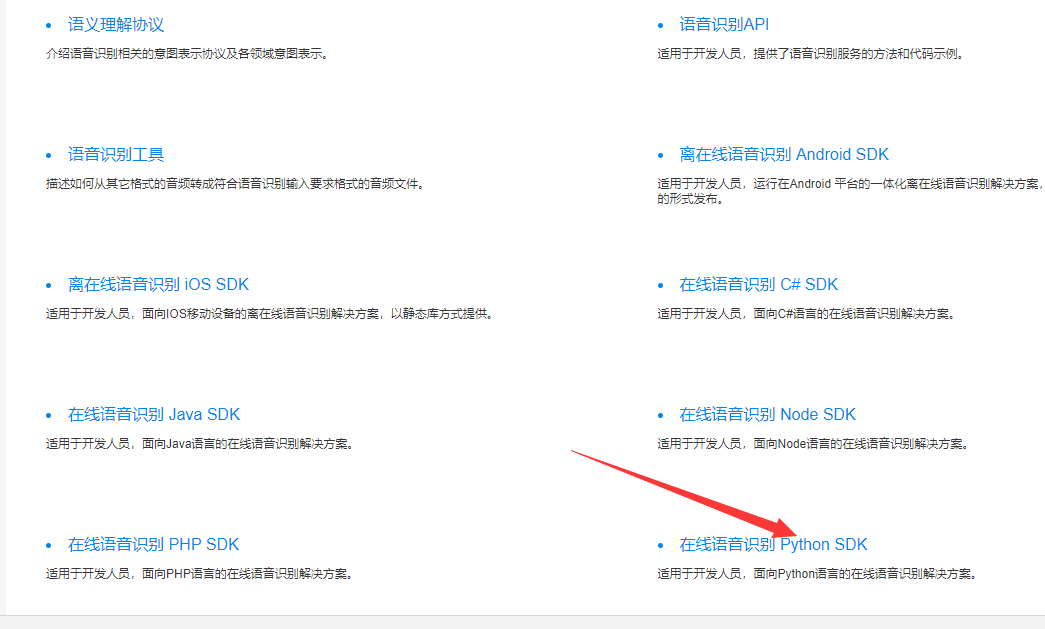
然后点击
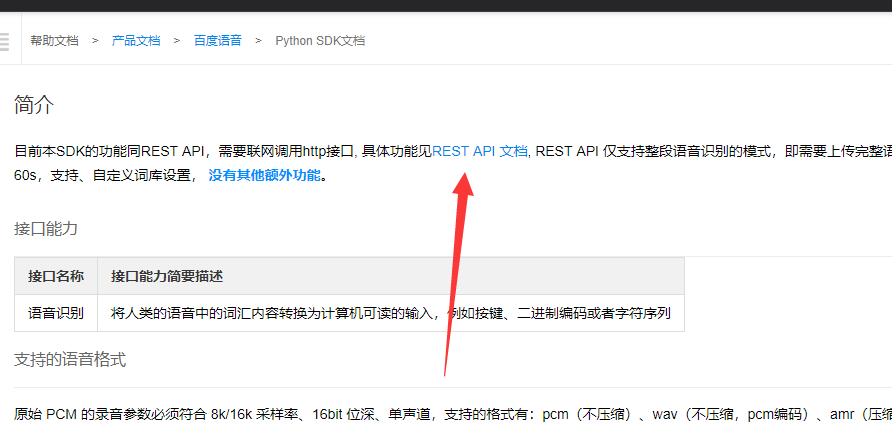
然后根据你的功能需求 选择语音识别或者合成
语音识别的只能识别pcm的格式一半windows和mac录音的文件都需要进行转码 所以我们要用ffemp软件进行转码
上面的百度语音的处理要导入百度语音的包
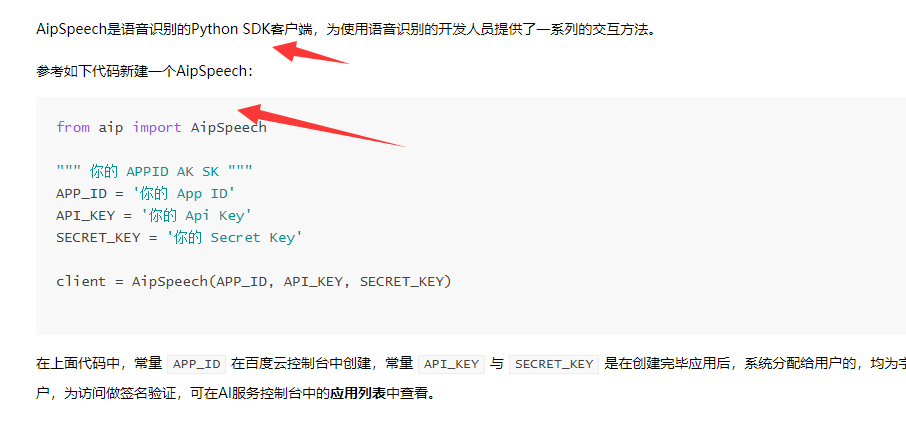
然后下面是代码测试
百度语音测试:


from aip import AipSpeech #导入 百度语音包from aip import AipNlp # 导入字然语言识别import tuling # 导入图灵import os""" 百度智能语音的使用 """# 如果是需要期对应的功能你的百度语音就需要打开对应的功能APP_ID = '11799980'API_KEY = '6WIC3XSGPt5lTEnBgbDZy43T'SECRET_KEY = 'vtck1Sbho2HC5NMGs6Ir2glQmWPjhj8u'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY)# ====输入汉字输出语音=====result = client.synthesis('人人为己,己为人人', 'zh', 1, { 'pid':9, 'per':'1', 'vol': 5,})# 识别正确返回语音二进制 错误则返回dict 参照下面错误码if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result)# =====语音转化为汉字======# 读取文件filepath = "录音.m4a" #获取你的语音文件def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") #修改你的文件的名字 with open(f"{filepath}.pcm", 'rb') as fp: return fp.read()# 识别本地文件liu = get_file_content(filepath)res = client.asr(liu, 'pcm', 16000, { 'dev_pid': 1536,})# print(res)if res.get("result"): print(res.get("result"))else: print(res)
#zh 是中文 1是代表声音是谁发的具体看文档
以上是对你的语音和文字的测试
下面可以对你的语音或者文字是否相似来进行判断
相似度:
选择相似度的时候你要选择你所对应的类型,选择处理哪种类型
然后再选择字然语言处理的sdk文档
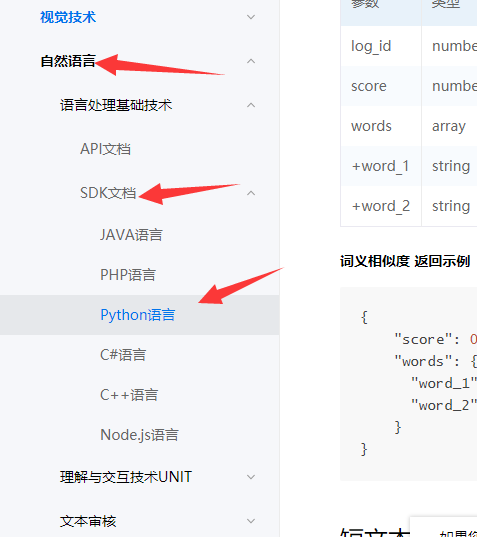
然后导入对应的处理的包:

自然语言处理 此处用的是短文本的处理 用来判断你的输入的文本是否相同
from aip import AipNlp #导入字然语言要处理的包""" 你的 APPID AK SK """APP_ID = '11799980'API_KEY = '6WIC3XSGPt5lTEnBgbDZy43T'SECRET_KEY = 'vtck1Sbho2HC5NMGs6Ir2glQmWPjhj8u'nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY)res = nlp_client.simnet("你叫什么","我也不知道") #进行相识度判断 如果都差不多# print(res)if res.get("score") > 0.7: # 如果差不多的相同达到0.7 print("你叫什么")else: #相识度不满足 print("说的我也不知道")